https://www.youtube.com/watch?v=1b7pXC1-IbE&t=771s
1편에 이어서 가보도록 하자.
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.by import By
driver = webdriver.Chrome()
driver.get("https://www.google.co.kr/imghp?hl=ko&authuser=0&ogbl")
elem = driver.find_element(By.NAME, "q")
elem.send_keys("박연진")
elem.send_keys(Keys.RETURN)근데, 재부팅하고 다시 실행하면 그대로 되어야 하는데, 아래와 같은 오류가 떴다.
(selenium) D:\python>d:/python/selenium/Scripts/python.exe d:/python/selenium/google.py
Traceback (most recent call last):
File "d:\python\selenium\lib\site-packages\selenium\webdriver\common\service.py", line 72, in start
self.process = subprocess.Popen(cmd, env=self.env,
File "C:\Program Files\WindowsApps\PythonSoftwareFoundation.Python.3.10_3.10.2544.0_x64__qbz5n2kfra8p0\lib\subprocess.py", line 971, in __init__
self._execute_child(args, executable, preexec_fn, close_fds,
File "C:\Program Files\WindowsApps\PythonSoftwareFoundation.Python.3.10_3.10.2544.0_x64__qbz5n2kfra8p0\lib\subprocess.py", line 1440, in _execute_child
hp, ht, pid, tid = _winapi.CreateProcess(executable, args,
FileNotFoundError: [WinError 2] 지정된 파일을 찾을 수 없습니다
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "d:\python\selenium\google.py", line 5, in <module>
driver = webdriver.Chrome()
File "d:\python\selenium\lib\site-packages\selenium\webdriver\chrome\webdriver.py", line 73, in __init__
self.service.start()
File "d:\python\selenium\lib\site-packages\selenium\webdriver\common\service.py", line 81, in start
raise WebDriverException(
selenium.common.exceptions.WebDriverException: Message: 'chromedriver' executable needs to be in PATH. Please see https://sites.google.com/a/chromium.org/chromedriver/home구글링을 해보니 여러가지 해결방법이 있었는데, 그건 정상적으로 chromedriver.exe와 google.py가 한 경로에 들어가있을 때, 그 디렉토리에서도 실행했는데, 안될때의 문제였다.
즉, 나는

가상환경에서 venv로 만들어놓은 selenium에서 D:\python\selenium으로 들어와서 python google.py를 눌러야하는데, D:\python에서 python google.py를 치고 있어서 경로를 찾을 수 없다고 나온 것 같다. 여튼 다시 제대로 google.py를 실행하게 되면 아래와 같이 나타나게 된다.
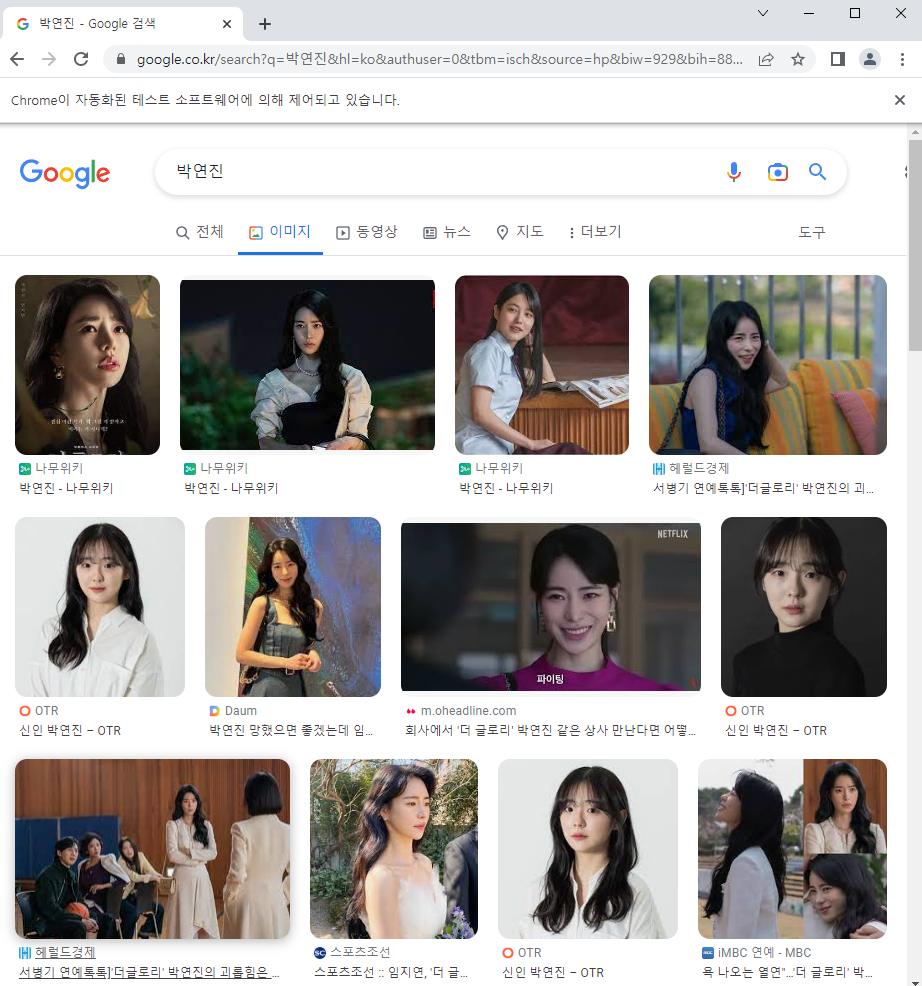
5. 이미지 다운로드
이제 이미지를 다운로드하는 코드를 작성해보자. 우리가 이미지 다운로드 받을 때를 생각해보면 마우스로 클릭하고 우클릭해서 다운로드 이런식으로 가져오는 경우가 많다. 그 행위를 코드로 자동화 시켜주면 되는 것이다. (검색 창을 찾고 검색어를 치고 엔터를 누르는 행위와 같이)
먼저 그럼 사진이 가지고 있는 고유 element 값을 살펴보자.

이미지에 해당하는 html 태그를 잘 살펴보면

저번 1편에서 검색창을 name = q 였다. 이번에는 class 가 rg_i 라고 되어있다. 보통 비슷한 객체들은 동일한 class를 가지고 있다. 이걸 파이썬에서 찾아보자.
driver.find_element라고 치게되면 아래와 같이 list가 나타난다.
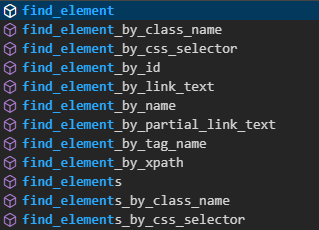
이때, element와 elements의 차이는 1개만 찾을거냐 여러개를 찾을거냐의 차이이다. 직관적으로는 by class name으로 찾을 것 같은데, 조코딩님은 by css selector로 찾아보기로 한다고 한다.
driver.find_elements_by_css_selector(".rg_i.Q4LuWd")그래서 rg_i Q4LuWd라고 되어있는 부분을 찾는 것으로 하는데, 중간에 . . 으로 연결해준다. 이걸 잘 모르면 CSS강좌를 참고하라는데, CSS강좌도 한 번 봐야겠다. 웹 크롤링엔 HTML에 대한 기본지식이 꽤나 바탕이 되어야 하는 것 같다.
지금 다시 보니 elements_by_css_selector라는건 css를 고르는 방식으로 고르나보다 라고 이해할 수 있다는 것을 깨달았다. 특정 이미지를 찾았는데, 이걸 클릭하는 방법을 모른다. (막혔다.) 이럴 때 구글링을 해본다.
driver.find_elements_by_css_selector(".rg_i.Q4LuWd")[0].click()
구글링을 해보면 뒤에 .click()을 치면된다고 한다. 조코딩님 께서는 elements들 중에 첫 번째 사진을 클릭해야하는 것이기 때문에 여기에 [0]을 붙여서 제일 첫 번째 사진을 클릭하도록 입력하였다.
큰 이미지의 다운로드도 똑같다. 마찬가지로 얘의 고유 값을 찾아가보자.

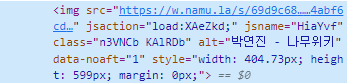
여기서 이미지를 다운받는 방법은 큰 이미지의 태그를 찾고, 그에 맞는 img src를 (주소)들어가서 다운받는 방법을 취한다. img src를 취하는 방법은 구글링해서 찾아보면 아래와 같다.
driver.find_element_by_id("idFOO").get_attribute("src")즉 뒤에다가 .get_attribute("src")를 입력하면 된다.
6. 시간 지연
이떄 하나 주의할 것이 있다. 클릭하거나 주소를 뭔가 가져오거나 할 때는 브라우저도 어느 정도의 시간이 필요하다. 그 시간을 지연시켜주는 코드를 중간에 통상 삽입해주어야 한다. 아래의 코드를 위쪽에 넣고
import time밑쪽에다가 time.sleep(3) 정도로 입력해보자. 그리고 아까 get_attribute를 추가한 저 code에 print를 씌워서 어떻게 출력하나 테스트해보자.
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.by import By
import time
driver = webdriver.Chrome()
driver.get("https://www.google.co.kr/imghp?hl=ko&authuser=0&ogbl")
elem = driver.find_element(By.NAME, "q")
elem.send_keys("박연진")
elem.send_keys(Keys.RETURN)
driver.find_elements_by_css_selector(".rg_i.Q4LuWd")[0].click()
time.sleep(3)
print(driver.find_element_by_css_selector(".n3VNCb").get_attribute("src"))근데 아래 이런식의 오류가 떴었다.
DevTools listening on ws://127.0.0.1:52742/devtools/browser/f3182ec2-e117-432f-a0ca-5ec23e4f907e
https://w.namu.la/s/69d9c687ee6147ba4e1e5591245157c484fea94a015b635471845dabaa27680af53c3c3ee899eabfe1a4ad57f67c99e3f7d8a816e63c935ae6538099d1465a875c585f39dc23efccfd2e604abf6cd3d912eeee1f6d6fbf818b16c1eff227206be9ee40deccadacde41174047655e350d
[249416:241240:0125/005605.594:ERROR:device_event_log_impl.cc(215)] [00:56:05.595] USB: usb_device_handle_win.cc:1046 Failed to read descriptor from node connection: 시스템에 부착된 장치가 작동하지 않습니다.
(0x1F)
e25-ecb6dc2d5be7
[248116:248916:0125/005757.461:ERROR:gpu_init.cc(523)] Passthrough is not supported, GL is disabled, ANGLE is
[199444:248100:0125/005759.302:ERROR:device_event_log_impl.cc(215)] [00:57:59.303] USB: usb_device_handle_win.cc:1046 Failed to read descriptor from node connection: 시스템에 부착된 장치가 작동하지 않습니다.
(0x1F)Passthrough is not supported, GL is disabled, ANGLE isted, GL is disabled, ANGLE is로 검색해보니 아래와 같이 들어가서 webGL을 enable시켜보라고 한다.
이 오류는 해결되었는데, 다시 아래와 같이 오류가 뜬다.
DevTools listening on ws://127.0.0.1:53796/devtools/browser/7df46980-1cbd-491c-af6e-d6eadf1e841c
[249196:250428:0125/010358.790:ERROR:device_event_log_impl.cc(215)] [01:03:58.790] USB: usb_device_handle_win.cc:1046 Failed to read descriptor from node connection: 시스템에 부착된 장치가 작동하지 않습니다. (0x1F)USB: usb_device_handle_win.cc:1046 Failed to read descriptor from node connection: 시스템에 부착된 장치가 작동하지 않습니다. (0x1F)
구글링을 해보니 아래와 같이 코드를 추가하라고 한다.
options = webdriver.ChromeOptions()
options.add_experimental_option("excludeSwitches", ["enable-logging"])
browser = webdriver.Chrome(options=options)나는 일단 오류가 해결되지가 않는다. USB: usb_device_handle_win.cc:1046이 계속 발생하여 찝찝하긴하지만, 일단 그냥 진행해본다. (구글에 1046이 없다.)
(selenium) D:\python\selenium>[251260:244672:0125/011231.943:ERROR:util.cc(134)]
Can't create base directory: C:\Program Files\Google\GoogleUpdater이런 오류도 발생했는데, 이건 Can't create base directory: C:\Program Files\Google에 가서 Googleupdator 폴더를 만들어주자.
7. 다운로드
python download image by url 이런식으로 검색하니 아래와 같이 사용해보라는 정보를 얻었다.
import urllib.request
urllib.request.urlretrieve("http://www.gunnerkrigg.com//comics/00000001.jpg", "00000001.jpg")이 코드를 추가해서 실행하면 뭔가 엄청 복잡한 오류가 뜬다.
Traceback (most recent call last):
File "d:\python\selenium\google.py", line 15, in <module>
urllib.request.urlretrieve(imgUrl, "test.jpg")
File "C:\Program Files\WindowsApps\PythonSoftwareFoundation.Python.3.10_3.10.2544.0_x64__qbz5n2kfra8p0\lib\urllib\request.py", line 241, in urlretrieve
with contextlib.closing(urlopen(url, data)) as fp:
File "C:\Program Files\WindowsApps\PythonSoftwareFoundation.Python.3.10_3.10.2544.0_x64__qbz5n2kfra8p0\lib\urllib\request.py", line 216, in urlopen
return opener.open(url, data, timeout)
File "C:\Program Files\WindowsApps\PythonSoftwareFoundation.Python.3.10_3.10.2544.0_x64__qbz5n2kfra8p0\lib\urllib\request.py", line 525, in open
File "C:\Program Files\WindowsApps\PythonSoftwareFoundation.Python.3.10_3.10.2544.0_x64__qbz5n2kfra8p0\lib\urllib\request.py", line 563, in error rllib\request.py", line 634, in http_response
return self._call_chain(*args)
File "C:\Program Files\WindowsApps\PythonSoftwareFoundation.Python.3.10_3.10.2544.0_x64__qbz5n2kfra8p0\lib\urllib\request.py", line 563, in errorrllib\request.py", line 496, in _call_chain
result = func(*args) rllib\request.py", line 496, in _call_chain
File "C:\Program Files\WindowsApps\PythonSoftwareFoundation.Python.3.10_3.10.2544.0_x64__qbz5n2kfra8p0\lib\urllib\request.py", line 643, in http_error_default rllib\request.py", line 643, in http_error_default
raise HTTPError(req.full_url, code, msg, hdrs, fp)
urllib.error.HTTPError: HTTP Error 403: ForbiddenHTTP Error 403: Forbidden가 핵심 에러인 것 같아서 찾아보니 웹 브라우저가 크롤링을 튕기는 것이라고 한다. (휴 ㅠㅠ)
파이썬3 웹 크롤링 HTTP error 403이 뜰 때 해결하는 방법
파이썬3에서 urllib.request를 사용할 때 HTTP Error 403이 뜰 때 해결하는 방법 다음과 같은 코드를 ...
blog.naver.com
이런 잔잔바리한 에러가 너무 많고 이를 일일이 고치기에는 방법이 뭔가 방법이 잘못된 것 같아서 유튜브 밑에 댓글을 찾았다. 다행히도 구세주가 있었다. 새벽별님이 코드를 올려주셨다. 우선 50개 다운까지의 코드 전문을 빌려오면 아래와 같다.

from outcome import capture
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.by import By
import time
import urllib.request
# 에러나는 부분이 있어서 추가
options = webdriver.ChromeOptions()
options.add_experimental_option("excludeSwitches", ["enable-logging"])
options.add_experimental_option("detach", True) # 브라우저 자동꺼짐 방지
# driver = webdriver.Chrome()
# 아래처럼 드라이버에 옵션 적용
driver = webdriver.Chrome(options=options)
# 위 부분 코드도 아래처럼 실행해야 되는 경우가 있습니다.(크롬 드라이버를 여러개 여러곳에 설치했을 경우)
# 에러메시지 내용: selenium.common.exceptions.WebDriverException: Message: 'chromedriver.exe' executable needs to be in PATH. Please see https://chromedriver.chromium.org/home
# driver = webdriver.Chrome(executable_path="D:\jocoding\selenium\chromedriver.exe", options=options)
# 크롬드라이버를 어느 경로의 드라이버를 실행할지 정확히 명시해줘야 합니다.
# 그런데 executable_path 이 옵션은 더이상 지원되지 않는다라는 메시지가 뜹니다.
# 다른 방법은? 아래 3줄을 삽입해서 드라이버의 경로를 지정해야 하는 것 같습니다.
# from selenium.webdriver.chrome.service import Service # 크롬드라이버 경로 지정을 위해
# ser = Service("D:\jocoding\selenium\chromedriver.exe") # (절대경로)
## ser = Service("selenium\chromedriver.exe") # 위 줄 코드는 이렇게 상대경로로 적어도 됩니다.(상대경로)
# driver = webdriver.Chrome(service=ser, options=options)
# 위와 같이 사용해야 하는 것 같습니다.
driver.get("https://www.google.co.kr/imghp?hl=ko&ogbl")
elem = driver.find_element(By.NAME, "q")
elem.send_keys("조코딩")
elem.send_keys(Keys.RETURN)
images = driver.find_elements(By.CLASS_NAME, "rg_i.Q4LuWd")
count = 1
for image in images:
image.click()
time.sleep(3)
# 아래 에러 나는 부분이 있어서 try except문 추가
try:
imgUrl = driver.find_element(
By.CLASS_NAME, "n3VNCb").get_attribute("src")
urllib.request.urlretrieve(imgUrl, str(count) + ".jpg")
except:
pass
count = count + 1이를 기반으로 다시 돌아가보자. 1개 다운받는 것 말고 애초에 목적이 여러가지 이미지 자동화 였으니, 그 방향으로 다시 코드를 작성해보자. elem.send_keys(Keys.RETURN) 밑의 코드를 수정하여 반복문으로 바꾸어 여러개의 사진을 동시에 다운받는 방식으로 바꾸면된다. find elements by css selector도 class name으로 찾는 것으로 바꾸자.
images= driver.find_elements(By.Class_name,".rg_i.Q4LuWd")
count=1
for image in images
image.click()
time.sleep(3)
이때, Try except문을 추가해서 에러가 났을 때, 예외처리하고 이를 사용해보도록 하자. 즉, try에서 예외가 발생하면 해당 줄에서 코드 실행을 중단하고 바로 except으로 가서 코드를 실행하도록 하는 문법이다.
파이썬 코딩 도장: 38.1 try except로 사용하기
Unit 38. 예외 처리 사용하기 예외(exception)란 코드를 실행하는 중에 발생한 에러를 뜻합니다. 다음과 같이 10을 어떤 값으로 나누는 함수 ten_div가 있을 때 인수에 따라 정상으로 동작하기도 하고 에
dojang.io
그래서 새벽별님 말대로 추가하면 아래와 같이 try에 대해 imgUrl 객체에 class name으로 검색하고 src를 찾은 값을 저장하고, urllib 모듈에서 request라는 모듈을 사용해서 urlretrieve라는 함수로 imgUrl에 대해 다운받는 기능을 구현한다. 단, 사진의 이름이 각기 다르게 저장되어야함으로 앞서 count=1이라고 저장한 변수를 string (문자열처리)하고 그에 대해 1.jpg라고 저장하는 것이다. 만약에 이게 오류가 뜨면 excpet처리하고 넘어간다. 그리고 count는 count +1 로 저장한다. 즉 맨처음에 1로 시작했으면 count2가 되는 것이다.
try:
imgUrl = driver.find_element(
By.CLASS_NAME, "n3VNCb").get_attribute("src")
urllib.request.urlretrieve(imgUrl, str(count) + ".jpg")
except:
pass
count = count + 1중간에 끊어버리긴했지만, jpg파일이 자동화되어 다운받아지는 것을 알 수 있다. 하 진짜 인간 세상의 종말이 정말 다가오는 것 같다.

여튼 코딩공부는 오늘 이정도로 끝.. 맨땅에 부딪히려니 나만안되고 너무 힘들다 ~!~! 도대체 이걸 4년동안 어떻게 배우는 겁니까 개발자들이여..
'일상 > 공학' 카테고리의 다른 글
| 공조냉동기계기사 증기 분사식 냉동기와 카르노 사이클 (0) | 2025.03.30 |
|---|---|
| 공조냉동기계기사 흡수식 냉동기 원리에 대해 간략히 알아보자 (0) | 2025.03.26 |
| 공조냉동기계기사 공부 내용 요약 남기기 챌린지 - 1 (0) | 2025.03.24 |
| [기사] 생성형 인공지능 신약 설계도 한다? 임상 2상까지 갔다 (0) | 2023.07.06 |
| 파이썬 크롤링 따라 해보는 기록 (구글 이미지 크롤링 + 업무자동화) 조코딩 님과 함께 - 1 (0) | 2023.01.24 |



댓글