* 맨 아래 S&P500그래프를 FREDAPI를 통해 그리는 코드를 적어 두었으니 참고하시기 바랍니다.
* 맨 처음 의도는 PER Band를 그리려는 것이었으나 FREDAPI로는 PER band그리는 것이 불가능하여 발행의 제목을 위와 같이 설정했습니다.
* FREDAPI에서는 Earning data가 없고, Yfinance에서는 Earnings에 대한 data가 String에러가 발생하는 것 같아서 가져오는데 뭔가 근본적인 문제가 있는 것 같습니다. 그래서 이 발행글 에서는 글의 맨 아래와 같이 S&P500의 단순 그래프만 그리는 결론을 내었습니다.

● 저평가 고평가 판단 가치의 가장 기본이 되는 PER band
가치 투자에서 가장 기본이 되는 저평가 주식매수 기법의 기초적인 방법인 저 PER에서의 매수 판단을 해보기 위해 S&P500의 PER band를 그려보도록하자. 일단 특정 기간부터 어떤 기간까지 S&P500 PER band를 그려내라고 했을 때 뱉은 코드는 다음과 같다. 일단 저번처럼 matplotlib.를 그리고 pandas datareader format을 통해 데이터를 읽어온 뒤 yahoo finance base에서 자료를 불러오자.
import matplotlib.pyplot as plt
import pandas_datareader as pdr
# Specify the start and end date for the data
start_date = '2022-01-01'
end_date = '2022-12-31'
# Fetch the data for the S&P500 index for specific period
data = pdr.get_data_yahoo('^GSPC', start=start_date, end=end_date)
# Check if Earnings column is present in the dataframe
if 'Earnings' in data.columns:
# Calculate the maximum and minimum PER
max_per = data['Close'].max() / data['Earnings'].max()
min_per = data['Close'].min() / data['Earnings'].min()
else:
print("Earnings column is not present in the dataframe.")
# You can get the earnings data from other sources
# Plot the chart
plt.plot(data.index, data['Close'] / data['Earnings'], label='S&P500 PER')
plt.plot(data.index, [max_per] * len(data.index), label='Max PER')
plt.plot(data.index, [min_per] * len(data.index), label='Min PER')
plt.legend()
plt.show()당연히 한 번에 안된다. 아래와 같은 오류가 떴다.
File "d:\python\selenium\perband.py", line 9, in <module>
data = pdr.get_data_yahoo('^GSPC', start=start_date, end=end_date)
File "d:\python\selenium\lib\site-packages\pandas_datareader\data.py", line 80, in get_data_yahoo
return YahooDailyReader(*args, **kwargs).read()
File "d:\python\selenium\lib\site-packages\pandas_datareader\base.py", line 253, in read
df = self._read_one_data(self.url, params=self._get_params(self.symbols))
File "d:\python\selenium\lib\site-packages\pandas_datareader\yahoo\daily.py", line 153, in _read_one_data
data = j["context"]["dispatcher"]["stores"]["HistoricalPriceStore"]
TypeError: string indices must be integersTypeError: string indices must be integers 이게 핵심인 것 같은데, 다시 물어보자.
나 : I got error message "TypeError: string indices must be integers." What should I do for adjusting to right code?
GPT : The error message "TypeError: string indices must be integers" typically occurs when you are trying to access an element of a data structure using a string index, but the data structure expects an integer index. In this case, it looks like the issue is with the line data['Close'] / data['Earnings']
→ Close와 Earning 쪽이 문제다 !
The most likely cause for this error is that the 'Earnings' column is not present in the dataframe or it's in different format, So it's not getting the proper data to perform the mathematical operation.
→ Earnings가 뭔가 포맷이 다를 수 있다. 그래서 파이썬코드가 계산하는데 뻑날 수 있다.
You can check whether the Earnings column is present in the dataframe by using the data.columns or data.info().
Another possibility is that the dataframe contains NaN values, which can cause issues when performing mathematical operations. You can check for NaN values using the data.isna().sum(). You can handle the missing values using the method like forward fill, backward fill, interpolation etc.
→ data.info()라는 함수로 Earnings 쪽 data를 체크해서 mathmatical하게 계산할 수 있게 뭐 고쳐나가라 !
You can also use other financial data providers such as FRED, IEX, ALPHAVANTAGE etc and check if these providers contains the Earnings data.
→ FRED나 다른 곳에서 earning data를 가져올 수도 있다.!
If the Earnings data is not available for the specific period, you should use a different data source or consider a different method for calculating the PER.
→ 어쨌든간에 한 datasource에서 earning이 없으면 다른 방식으로 자료를 갖다 써야한다 !
를 보고 How can I modify the python code based on FRED Earnings data? 라고 물었더니
GPT :
You can use the pandas_datareader library to fetch the Earnings data from the Federal Reserve Economic Data (FRED) database.
First, you will need to install the fredapi and pandas package, you can do this by running the following command:
pip install fredapi pandasThen you can use the fredapi package to fetch the Earnings data and pandas to handle the dataframe. You can use the get_series() method to fetch the Earnings data from FRED.
Here's an example of how you can modify the code to use the Earnings data from FRED:
(코드 주고)
In this code, the fred.get_series('SP500') fetches the Earnings data for S&P500 from FRED. Before merging the dataframe, you should check for missing values and rename the column to 'Earnings' and then merge it with the 'data' dataframe.
Please note that you need to replace 'YOUR_API_KEY' with your actual API key for accessing data from FRED. If you don't have one, you can sign up for a free API key on the FRED website.
오 뭐가 FRED에서 뭔가 자료를 가져오는게 일단 되긴 되나보다. Earnings data를 fredapi로부터 받아서 아래와 같이 코드를 수정하였다. 실행해보자.
import matplotlib.pyplot as plt
from fredapi import Fred
import pandas as pd
# Initialize the FRED api
fred = Fred(api_key='YOUR_API_KEY')
#Fetch the Earnings data from FRED
earnings = fred.get_series('SP500')
# Specify the start and end date for the data
start_date = '2022-01-01'
end_date = '2022-12-31'
# Fetch the data for the S&P500 index for specific period
data = pdr.get_data_yahoo('^GSPC', start=start_date, end=end_date)
# check for missing values
print(earnings.isna().sum())
# rename the column
earnings.rename('Earnings', inplace=True)
# merge the dataframe
data = pd.concat([data, earnings], axis=1)
# check if Earnings column is present in the dataframe
if 'Earnings' in data.columns:
# Calculate the maximum and minimum PER
max_per = data['Close'].max() / data['Earnings'].max()
min_per = data['Close'].min() / data['Earnings'].min()
else:
print("Earnings column is not present in the dataframe.")
# You can get the earnings data from other sources
# Plot the chart
plt.plot(data.index, data['Close'] / data['Earnings'], label='S&P500 PER')
plt.plot(data.index, [max_per] * len(data.index), label='Max PER')
plt.plot(data.index, [min_per] * len(data.index), label='Min PER')
plt.legend()
plt.show()무지성으로 RUN누르니까 ValueError: Bad Request. The value for variable api_key is not a 32 character alpha-numeric lower-case string. Read https://fred.stlouisfed.org/docs/api/api_key.html for more information. 와 같이 나타난다.
St. Louis Fed Web Services: API Key
API Keys Request or view your API keys Note that you cannot request or view your API keys without first logging into your fredaccount.stlouisfed.org user account. All web service requests require an API key to identify requests. Developers should request a
fred.stlouisfed.org
GPT에서도 말했듯이 FRED에 가입해서 free API Key를 입력해보자. 회원가입을 대충하고 API Keys를 가보면
아래처럼 Request API Key가 있다.
그럼 Request API Key를 다시 누르면 아래와 같이 창이 나오는데,
걍 주절주절 아무렇게나 썼다. 그럼 위쪽에 초록색 창이 뜬다. 이걸 그럼 코드에 다시 집어 넣어주자.

여기에다가 넣자.
fred = Fred(api_key='YOUR_API_KEY')어김없이 오류가 떴다.
NameError: name 'pdr' is not defined. Did you mean: 'pd'?GPT형님께 물어보니 pandas_datareader module을 import하는 것을 깜빡하셨다고 한다. ㅋㅋㅋㅋ 귀엽.. 아래의 pandas datareader module을 import하고 그것을 pdr이라고 정의해주자.
import pandas_datareader as pdr어라? 근데 다시 TypeError: string indices must be integers 오류가 떴다. 문의해보니
I apologize for the confusion. The error message "string indices must be integers" is indicating that the data variable is a string and not a dictionary, and it's trying to access its values using an index, which is not possible.
It seems that the pdr.get_data_yahoo('^GSPC', start=start_date, end=end_date) method is not working properly and returning a string instead of a dataframe. One of the reasons for this could be that the yahoo finance API has changed or discontinued, which is causing the method to fail.
To fix this issue, you can use other financial data providers such as FRED, IEX, ALPHAVANTAGE etc, or you can use other libraries such as yfinance which can be used to fetch the data from yahoo finance.
Here's an example of how you can use the yfinance library to fetch the data for the S&P500 index:
Yahoo Finance API에서 뭔가 정의하는 조항이 바뀐 것 같다고 한다. 그래서 S&P500의 index에서 data를 fetch하는 방법에 대한 cdoe를 작성해줬다.
import yfinance as yf
# Specify the start and end date for the data
start_date = '2022-01-01'
end_date = '2022-12-31'
# Fetch the data for the S&P500 index for specific period
data = yf.download('^GSPC', start=start_date, end=end_date)
# check if Earnings column is present in the dataframe
if 'Earnings' in data.columns:
# Calculate the maximum and minimum PER
max_per = data['Close'].max() / data['Earnings'].maxyfinance를 yf라고 정의하고, start date와 end date를 객체로 정의해준 뒤, yf.패키지의 기능 중 download라는 기능을 사용하여 ^GSPC (S&P500의 ticker)의 2022-01-01부터 2022-12-31까지의 정보를 가져와서 data라는 객체에 넣고, 만약에 'Earnings'가 data.columns에 있으면 뭔가 동작을 사부작사부작 하는 것이다. 여튼 다시 수정된 코드는 아래와 같다.
import matplotlib.pyplot as plt
from fredapi import Fred
import yfinance as yf
import pandas as pd
# Initialize the FRED api
fred = Fred(api_key='Your API KEYS')
#Fetch the Earnings data from FRED
earnings = fred.get_series('SP500')
# Specify the start and end date for the data
start_date = '2022-01-01'
end_date = '2022-12-31'
# Fetch the data for the S&P500 index for specific period
data = yf.download('^GSPC', start=start_date, end=end_date)
# check for missing values
print(earnings.isna().sum())
# rename the column
earnings.rename('Earnings', inplace=True)
# merge the dataframe
data = pd.concat([data, earnings], axis=1)
# check if Earnings column is present in the dataframe
if 'Earnings' in data.columns:
# Calculate the maximum and minimum PER
max_per = data['Close'].max() / data['Earnings'].max()
min_per = data['Close'].min() / data['Earnings'].min()
# Plot the chart
plt.plot(data.index, data['Close'] / data['Earnings'], label='S&P500 PER')
plt.plot(data.index, [max_per] * len(data.index), label='Max PER')
plt.plot(data.index, [min_per] * len(data.index), label='Min PER')
plt.legend()
plt.show()
else:
print("Earnings column is not present in the dataframe.")RUN 시키면 어림도 없지 ~! 오류메시지는 아래와 같다.
TypeError: Cannot join tz-naive with tz-aware DatetimeIndex이걸 다시 물어봤더니, 아래와 같다고 함.
The error message "TypeError: Cannot join tz-naive with tz-aware DatetimeIndex" indicates that there is a mismatch in the timezone information between the two DataFrames you are trying to concatenate.
In this case, it seems that the data DataFrame has a timezone-aware DatetimeIndex, while the earnings DataFrame has a timezone-naive DatetimeIndex.
In order to concatenate these two DataFrames, you need to make sure that both DataFrames have the same timezone information.
You can use the data.index.tz and earnings.index.tz to check the timezone information of the two DataFrames. If the earnings DataFrame has no timezone information, you can use the earnings.index.tz_localize() function to assign the same timezone as the data DataFrame.
Here's an example of how you can modify the code to fix this error:
대충 뭔말인고 하니, 어떤 두 data의 시간대가 안맞나 보다. timezone-aware vs timezone-naive 이 2개가 되어있으면 안되나보다. 이 2개를 합치려면 같은 timezone 정보로 바꿔줘야하는데, earnings이 timezone 정보가 없으면 earnings.index.tz_localize()라는 함수로 같은 timezone에다가 DATAFRAME을 넣을 수 있다고 한다. 요약하면 시간 단위를 하나로 통일 ! 그래서 고치면
import matplotlib.pyplot as plt
from fredapi import Fred
import yfinance as yf
import pandas as pd
# Initialize the FRED api
fred = Fred(api_key='YOUR_API_KEY')
#Fetch the Earnings data from FRED
earnings = fred.get_series('SP500')
# Specify the start and end date for the data
start_date = '2022-01-01'
end_date = '2022-12-31'
# Fetch the data for the S&P500 index for specific period
data = yf.download('^GSPC', start=start_date, end=end_date)
# check for missing values
print(earnings.isna().sum())
# rename the column
earnings.rename('Earnings', inplace=True)
# localize the earnings dataframe
earnings.index = earnings.index.tz_localize(data.index.tz)
# merge the dataframe
data = pd.concat([data, earnings], axis=1)
# check if Earnings column is present in the dataframe
if 'Earnings' in data.columns:
# Calculate the maximum and minimum PER
max_per = data['Close'].max() / data['Earnings'].max()
min_per = data['Close'].min() / data['Earnings'].min()
# Plot the chart
plt.plot(data.index, data['Close'] / data['Earnings'], label='S&P500 PER')
plt.plot(data.index, [max_per] * len(data.index), label='Max PER')
plt.plot(data.index, [min_per] * len(data.index), label='Min PER')
plt.legend()
plt.show()
else:
print("Earnings column is not present in the dataframe.")Your API Keys자리에 자신의 API Keys 입력해야된다는 것 잊지말고 다시 RUN! 이번엔 오류가 안떴는데 뭔가 이상하다.
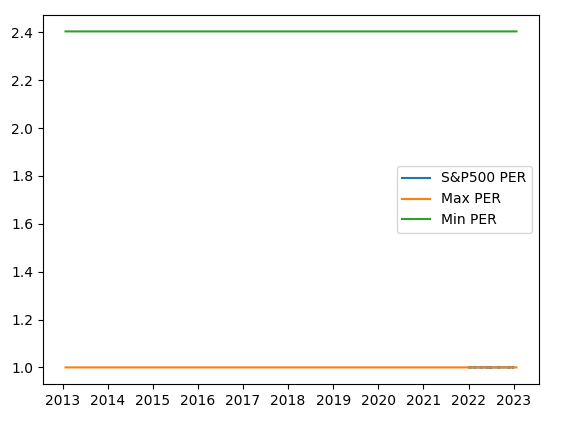
아 뭔가 코딩의 설계를 잘못했음을 깨달았다. 증권사들이 그리는 S&P500의 PER band chart는 과거의 EPS를 기준으로 거기다가 그래프에 각각 특정 PER를 곱해서 그걸 band로 각각 그리고, 현재가가 그려져야 한다는 것이다.
예를들면, S&P500의 역사적 Max Per가 25, Min Per가 11이라고 했으면, 각 시기의 S&P500의 EPS * 25 한 값의 그래프, 그리고 각 시기의 S&P500의 EPS * 11한 값의 그래프, 그리고 S&P500의 주가가 같이 그려져야 한다. 다시 GPT형님께 물어보자.
Thanks for offering nice code! You taught me very much. However, I realized that I was wrong. Because, PER band graph is drawn by this logic. :
1. Figure out the maximum PER of specific ticker historically or just specific period that I designated.
2. Figure out the minimum PER of specific ticker historically or just specific period that I designated.
3. There is EPS value of specific ticker by the time. So, We know about one line for maximum value of specific ticker which is calculated by PER*EPS, the most expensive premium line. and another line for minimum value of specific ticker which is calculated by PER*EPS, the cheapest premium line.
4. So, There are 2 lines for assumption value of specific ticker.
5. And We know the value of specific ticker by the time. Add this line.
6. Therefore, We have 3 lines in graphs. In other words, Band means the range from maximum premium line to minimum premium line. and I can figure out the historical premium trends of specific ticker.
So Could you change the python code based on logic above? I'm sorry for writing so long. :)
아~ 알고보니 지금 PER을 그린게아니라 EPS를 그린 것 같다. 답변은 아래와 같다.
import matplotlib.pyplot as plt
import yfinance as yf
import pandas as pd
# Specify the ticker symbol
ticker = 'AAPL'
# Specify the start and end date for the data
start_date = '2022-01-01'
end_date = '2022-12-31'
# Fetch the data for the ticker for specific period
data = yf.download(ticker, start=start_date, end=end_date)
#Calculate the max and min per
max_per = data['Close'].max() / data['Earnings'].max()
min_per = data['Close'].min() / data['Earnings'].min()
#Calculate the max and min values based on EPS
data['Max Value'] = data['Earnings']*max_per
data['Min Value'] = data['Earnings']*min_per
# Plot the chart
plt.plot(data.index, data['Close'], label='Close')
plt.plot(data.index, data['Max Value'], label='Max Value')
plt.plot(data.index, data['Min Value'], label='Min Value')
plt.legend()
plt.show()그랬더니 역시 녹록치 않다. 다른 에러를 뱉는다. KeyError: 'Earnings' 이렇게 뱉는다. 아까 yfinance에서 Earning의 data에 뭔가 문제가있었기 때문에 (위에서는 string index 에러가 떴었다) 다시 fred에 기반한 code로 바꿔달라고 주문을 해본다.
I think there are no 'Earnings' data in yfinance. Could you please change the code based on FRED?
import matplotlib.pyplot as plt
from fredapi import Fred
import yfinance as yf
import pandas as pd
# Initialize the FRED api
fred = Fred(api_key='YOUR_API_KEY')
# Specify the ticker symbol
ticker = 'AAPL'
# Specify the start and end date for the data
start_date = '2022-01-01'
end_date = '2022-12-31'
# Fetch the data for the ticker for specific period
data = yf.download(ticker, start=start_date, end=end_date)
# Fetch the Earnings data from FRED
earnings = fred.get_series(ticker + 'EPS')
# merge the dataframe
data = pd.concat([data, earnings], axis=1)
#Calculate the max and min per
max_per = data['Close'].max() / data['Earnings'].max()
min_per = data['Close'].min() / data['Earnings'].min()
#Calculate the max and min values based on EPS
data['Max Value'] = data['Earnings']*max_per
data['Min Value'] = data['Earnings']*min_per
# Plot the chart
plt.plot(data.index, data['Close'], label='Close')
plt.plot(data.index, data['Max Value'], label='Max Value')
plt.plot(data.index, data['Min Value'], label='Min Value')
plt.legend()
plt.show()에러가 또 발생했다. ValueError: Bad Request. The series does not exist. 라고 한다. 문의해보니 아래와 같이 나온다.
The error message "Bad Request. The series does not exist." suggests that the series you're trying to fetch from FRED, 'SP500EPS', does not exist in the FRED database.
You can check the series code on the FRED website to verify if the series is available and if not, you could try searching for a similar series that contains the Earnings data for S&P500.
Also, S&P500 is an index, not a stock, so it doesn't have a Earnings Per Share (EPS) value as it is not a company.
You can use other financial ratio such as P/E ratio of S&P500 index, but you need to use other package such as quandl, yahoo_fin, etc.
Please let me know if you need any further assistance.
이말은 즉슨, EPS data가 없다는 것이다 !!! 다음 편에서 quandl이라는 것을 통해 다시 그려보도록 하겠다. 아쉬워서 S&P500의 그래프만이라도 그릴 수 없냐고 부탁했더니 아래와 같이 만들어 줬다. (API키를입력)
import matplotlib.pyplot as plt
from fredapi import Fred
import pandas as pd
# Initialize the FRED api
fred = Fred(api_key='YOUR_API_KEY')
# Specify the series code for S&P500
series_code = 'SP500'
# Specify the start and end date for the data
start_date = '2022-01-01'
end_date = '2022-12-31'
# Fetch the data for the series
data = fred.get_series(series_code, start_date, end_date)
# Plot the chart
plt.plot(data.index, data, label='S&P500')
plt.legend()
plt.show()
코드를 하나하나씩 좀 까보면서 이해해보는 과정은 아래 영상 중간 부분에 담아두었습니다. 2탄에서..
'미래걱정 > 주식' 카테고리의 다른 글
| S&P500 그래프와 장단기금리차의 그래프를 같이 그려보자 (with Chat gpt, ax1.twinx) - 2 (0) | 2023.01.27 |
|---|---|
| yfinance로 주가 저장 및 크롤링하기, csv저장, 그래프 그리기 등 (with chat gpt) (0) | 2023.01.26 |
| Yahoo finance에서 Python으로 마켓 데이터 가져오기 [파이썬 왕초보의 친절한 의식의흐름] - 1 (0) | 2023.01.22 |
| 한상희 위원과 함께하는 2023년도 주식시장 전망 (삼프로TV, STEPS 리뷰) (0) | 2023.01.08 |
| 주식은 답이 아니다? 박석중 파트장님과 나의 생각 [삼프로TV 유튜브리뷰] (2) | 2023.01.04 |




댓글